通过源码分析Go的基本类型-Map(哈希表),源代码版本:go 1.16.5.
一、原理
map一般称之为哈希映射表或者哈希表,key无序。
要理解map就要分析两个要素:哈希函数和冲突解决方法。
哈希函数的标准:结果是否平均分配。结果越不平均,更容易导致哈希碰撞,影响读写性能。
冲突解决: 由于哈希的输出是有限的,但输入是无限的,所以哈希碰撞是不可避免的。
常见的解决方法有:开放寻址法和拉链法。
1. 开放寻址法
核心思想是依次探测和比较数组中的元素以判断目标键值对是否存在于哈希表中。
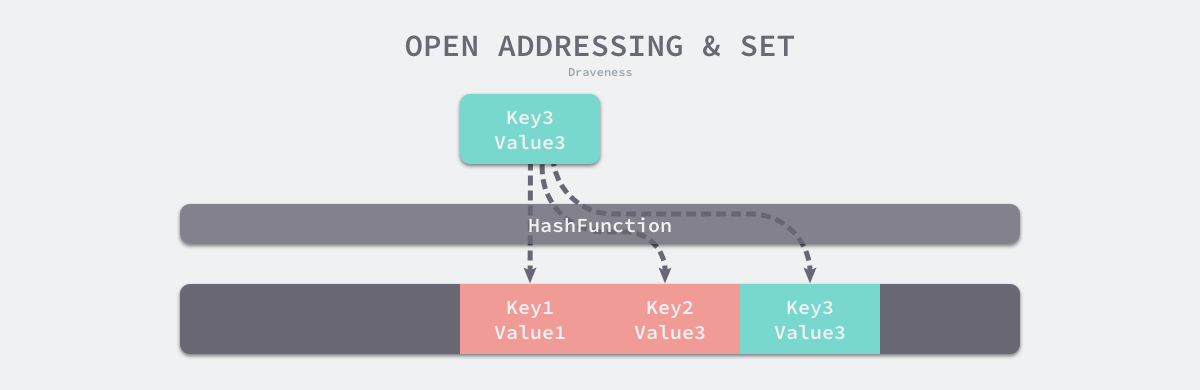
如上图所示,key1、key2、key3哈希冲突。那么key3就会存储到key2之后的位置。
当读取时,先根据key3的高位寻址到key1,然后取整个key的哈希比较,发现哈希不一致,则继续往后面取,直到定位到key3或空内存(空内存表示key不存在)。
开放寻址法衡量性能指标的最大因素是:装载因子(数组中元素的数量与数组大小的比值)。 简单理解,就是装载率越大,key3需要往后移的此处就越多,查询和写入的速度就越慢。 如果装载率为100%,则表示哈希冲突率为100%,查询和写入的时间复杂度就是线性的O(n)。
2. 拉链法
拉链法相对更为常用,和开放寻址法相比:实现更为复杂,但是存储空间利用率更低,寻址的速度也相对更快。Go使用的是拉链法。
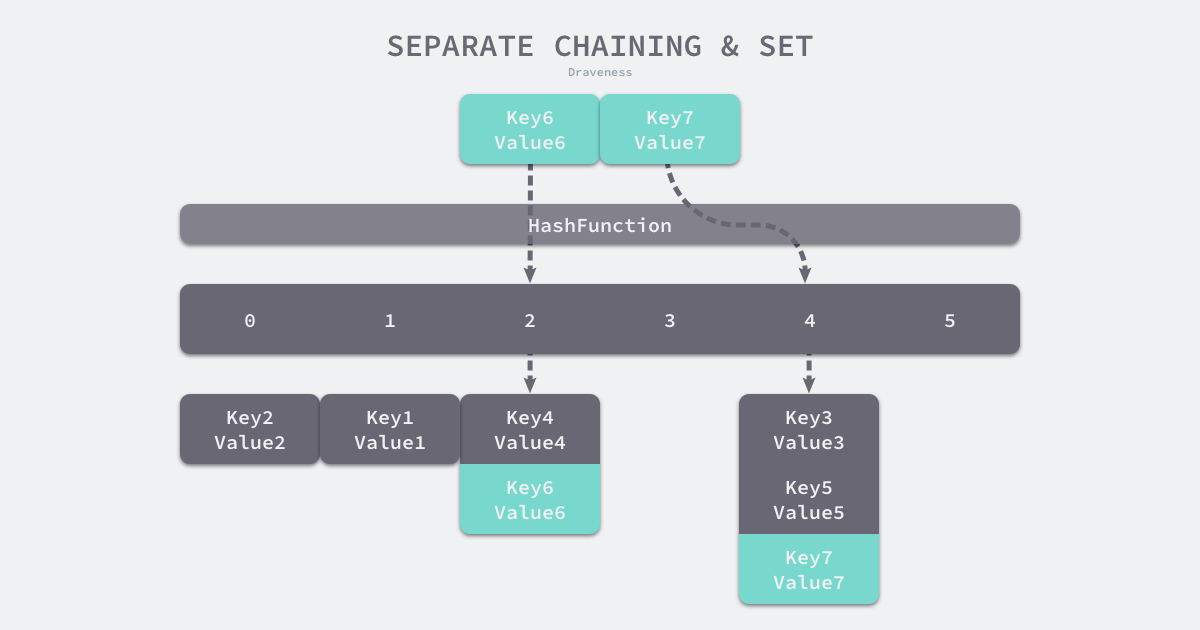
其核心是按照桶来管理哈希冲突的key。key6进来是,首先经过哈希函数确定所在的桶,然后通过便利桶中的链表来确定其所在的位置。
当插入key6时,首先根据哈希结果选择2号桶,然后遍历链表。通过哈希比对,key4 ≠ key6 ,所以往下找。 最后确定链表尾部均不相同后,将key6追加到链表尾部。如果发现一致的key,覆盖value。
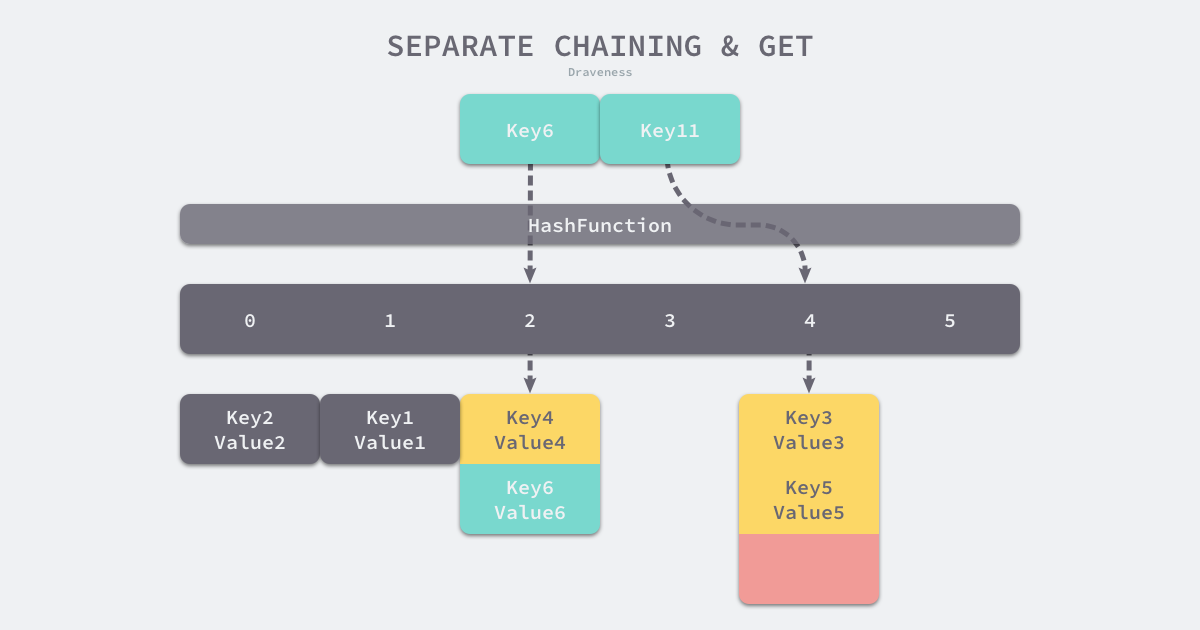
当查找时,和插入相同,首先确定桶,然后遍历。如key11,遍历桶的链表结束仍未匹配到key,则认定key不存在。
拉链法下的装载因子=元素数量 / 桶的数量。装载因子一般不超过1,当装载因子过大时,会触发哈希的扩容,通过增加桶的数量,来保护性能的稳定性。
二、数据结构
const (
// bucket能存放的元素数量。 8个
bucketCntBits = 3
bucketCnt = 1 << bucketCntBits
// Maximum average load of a bucket that triggers growth is 6.5.
// Represent as loadFactorNum/loadFactorDen, to allow integer math.
loadFactorNum = 13
loadFactorDen = 2
// 直接存储的Key/Value的最大限制,如果查过这个限制,则会转换位指针存储到bucket中。
maxKeySize = 128
maxElemSize = 128
// data offset should be the size of the bmap struct, but needs to be
// aligned correctly. For amd64p32 this means 64-bit alignment
// even though pointers are 32 bit.
// 数据偏移量对齐bmap
dataOffset = unsafe.Offsetof(struct {
b bmap
v int64
}{}.v)
// 下面是tophash可能被定义的值,有时候也会定位为一些特殊的标记。
// 还有每一个bucket(包括overflow的bucket)在exacuated期间的state(只有写操作才会调用evacuate())
emptyRest = 0 // this cell is empty, and there are no more non-empty cells at higher indexes or overflows.
emptyOne = 1 // this cell is empty
evacuatedX = 2 // evacuated的上限 // key/elem is valid. Entry has been evacuated to first half of larger table.
evacuatedY = 3 // evacuated的下限 // same as above, but evacuated to second half of larger table.
evacuatedEmpty = 4 // cell is empty, bucket is evacuated.
// 小于5的tophash,都是系统定义的状态标记。
minTopHash = 5 // minimum tophash for a normal filled cell.
// flags
iterator = 1 // there may be an iterator using buckets
oldIterator = 2 // there may be an iterator using oldbuckets
// 写标记
hashWriting = 4 // a goroutine is writing to the map
// 扩容是否是1倍
sameSizeGrow = 8 // the current map growth is to a new map of the same size
// sentinel bucket ID for iterator checks
// 迭代期间,bucket是否正在迁移的检查标记
noCheck = 1<<(8*sys.PtrSize) - 1
)
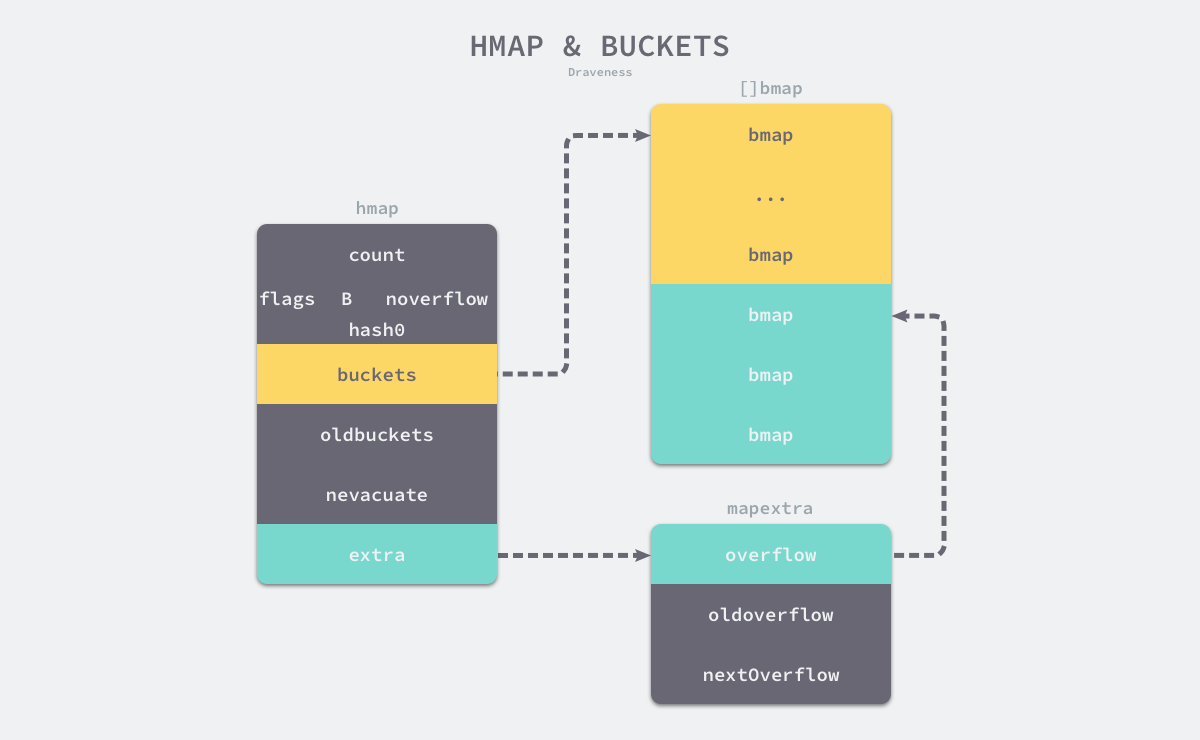
map的核心是hmap。
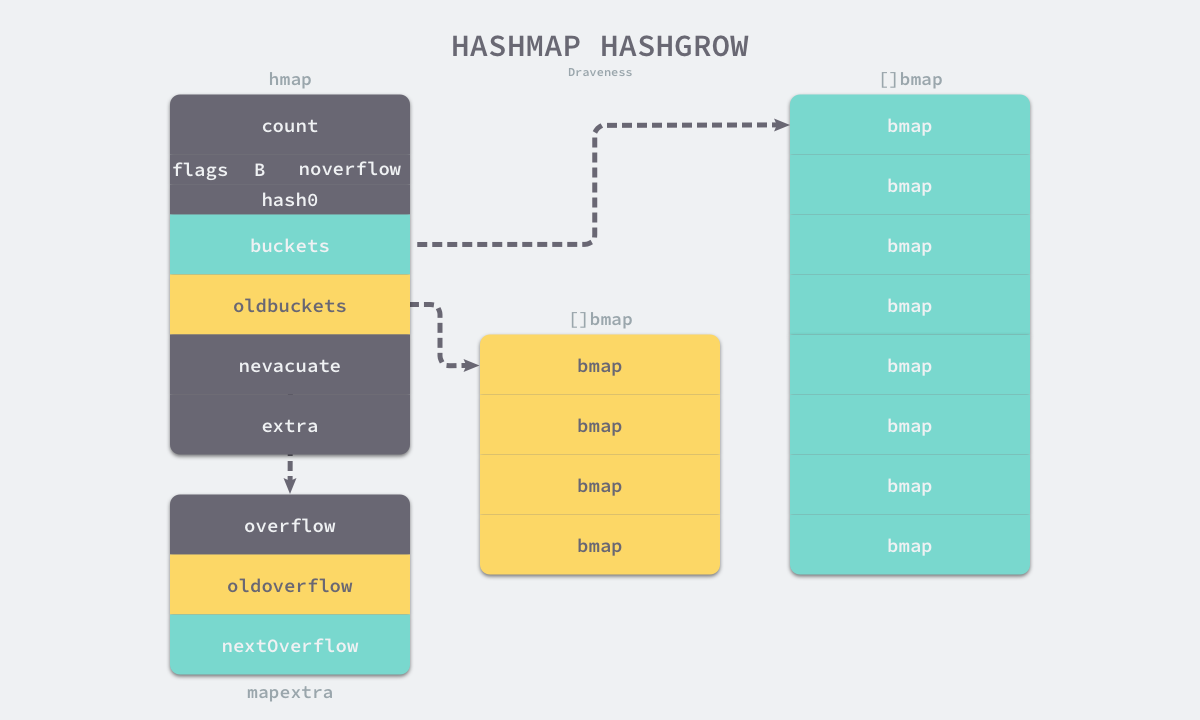
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/gc/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // map中的元素个数,必须放在首位,可以通过内存对齐的特点来提升len()函数的性能。
// 写标记
flags uint8
B uint8 // 2^B = 桶的数量
noverflow uint16 // 溢出桶的估算值
hash0 uint32 // map的哈希函数因子
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // 扩容时,存放扩容前的桶。其size为扩容后的一半, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // 溢出桶
}
```
可知,buckets和extra在内存上是不连续的,所以我们将其分为正常桶和溢出桶。
```text
type mapextra struct {
// 限于key 和 value 都不是指针,并且可以被inline(size<=128 bit)
// 可以用mapextra来存储overflow,避免扫描整个map
// overflow = bmap.buckets.overflow 指向相同的buckets
// oldoverflow = bmap.oldbuckets.overflow 指向相同的buckets
overflow *[]*bmap
oldoverflow *[]*bmap
// 指向一个空闲的overflow bucket的指针
nextOverflow *bmap
}
每个hmap含有8个正常桶,桶的结构体是bmap。每个桶可以存放8对key-value,当哈希表中存储的数据过多,单个桶已经装满时就会使用 extra.nextOverflow 中的桶来存储溢出的数据。
bmap存储的是key哈希值的高8位,通过高8位的比对,可以减少访问桶中键值对的次数来提升性能。
type bmap struct {
tophash [bucketCnt]uint8
}
在运行时,bmap不止tophash,如key和value的类型、溢出指针等只能在编译时推导。
runtime.bmap中的其他字段在运行时也是通过计算出内存的地址来访问的,所以定义中没有相对应的字段,下面通过编译函数cmd/compile/internal/gc.bmap来重建bmap:
type bmap struct {
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
}
正常桶的数量不会超过8个,对于溢出的数据通过扩容哈希表或者使用溢出桶来存储。不过溢出桶是临时的方案,如果创建了过多的溢出桶,也会导致哈希表的扩容。
三、初始化
Go初始化哈希表有两种方式:字面量初始化和运行时初始化。
形如make(map,1)为字面量初始化,形如var m *map[string]int 为运行时初始化。
字面量初始化
形如:
make(map[k]v, hint)
// 如果编译器认为map和第一个bucket可以直接创建在栈上,那么h和bucket可能是非空的。
// 如果h不为空,则可以直接使用h创建map
// 如果bucket不为空,则可以直接复用为本map的第一个bucket(覆盖)
func makemap(t *maptype, hint int, h *hmap) *hmap {
// 计算需要申请的内存
mem, overflow := math.MulUintptr(uintptr(hint), t.bucket.size)
if overflow || mem > maxAlloc {
// 如果内存溢出或者超过最大内存申请限制,则使用lazy模式
hint = 0
}
// 如果h为空,则初始化一个
if h == nil {
h = new(hmap)
}
// 设置哈希函数的因子
h.hash0 = fastrand()
// 计算需要生成bucket的数量
B := uint8(0)
for overLoadFactor(hint, B) {
// 为保证装载率不超过1,为每个元素分配一个bucket
B++
}
h.B = B
// 如果B==0,buckets将由mapassign进行lazy分配
// 如果元素个数比较多,那么buckets的分配会消耗一定的时间
if h.B != 0 {
var nextOverflow *bmap
// 根据元素类型,创建保存bucket数据的数组
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
if nextOverflow != nil {
// 如果有溢出桶,则将将溢出桶指针指向hmap
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h
}
如果桶的数量大于2^4,则会创建2^(B-4)个溢出桶。
func makeBucketArray(t *maptype, b uint8, dirtyalloc unsafe.Pointer) (buckets unsafe.Pointer, nextOverflow *bmap) {
base := bucketShift(b)
nbuckets := base
if b >= 4 {
nbuckets += bucketShift(b - 4)
sz := t.bucket.size * nbuckets
up := roundupsize(sz)
if up != sz {
nbuckets = up / t.bucket.size
}
}
buckets = newarray(t.bucket, int(nbuckets))
if base != nbuckets {
nextOverflow = (*bmap)(add(buckets, base*uintptr(t.bucketsize)))
last := (*bmap)(add(buckets, (nbuckets-1)*uintptr(t.bucketsize)))
last.setoverflow(t, (*bmap)(buckets))
}
return buckets, nextOverflow
}
根据上述代码,我们能确定在正常情况下,正常桶和溢出桶在内存中的存储空间是连续的,只是被 runtime.hmap 中的不同字段引用。
形如:
hash := map[string]int{
"1": 2,
"3": 4,
"5": 6,
}
在编译时,会通过 cmd/compile/internal/gc.maplit 初始化:
func maplit(n *Node, m *Node, init *Nodes) {
a := nod(OMAKE, nil, nil)
a.Esc = n.Esc
a.List.Set2(typenod(n.Type), nodintconst(int64(n.List.Len())))
litas(m, a, init)
entries := n.List.Slice()
if len(entries) > 25 {
...
return
}
...
}
也就是说,如果元素不超过25个,编译器会将其转换为如下代码
hash := make(map[string]int, 3)
hash["1"] = 2
hash["3"] = 4
hash["5"] = 6
如果超过,则为key和value分别创建数组,然后通过for循环,插入数据。
hash := make(map[string]int, 26)
vstatk := []string{"1", "2", "3", ... , "26"}
vstatv := []int{1, 2, 3, ... , 26}
for i := 0; i < len(vstak); i++ {
hash[vstatk[i]] = vstatv[i]
}
使用字面量初始化的过程都会使用 Go 语言中的关键字 make 来创建新的哈希,并通过最原始的数组向哈希表追加元素。
运行时
当创建的哈希表被分配到栈上,且容量小于8时(没有溢出桶)。Go在编译时会使用makemap_small来进行快速的初始化。
func makemap_small() *hmap {
h := new(hmap)
h.hash0 = fastrand()
return h
}
相对makemap,makemap_small有几个优势:
- buckets的分配可以由mapassign进行分配,减少buckets的预占用;
- 节省了buckets的内存分配时间。
四、查询
对于操作:value,ok :=aMap[key]。编译器会按照查询的结果来选择指定查询内部查询方法。
形如:v:=m[]key 会被编译器替换为mapaccess1(maptype, hash, &key),形如v,exist:=m[]key会被编译器替换为mapaccess2(maptype, hash, &key)
mapaccess1返回指向目标值的指针,mapaccess2则多返回一个用于表示当前key是否存在的bool值。
下面对mapaccess2举例解析。
func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool) {
// 竞态检查,此处不展开
if raceenabled && h != nil {
callerpc := getcallerpc()
pc := funcPC(mapaccess2)
racereadpc(unsafe.Pointer(h), callerpc, pc)
raceReadObjectPC(t.key, key, callerpc, pc)
}
if msanenabled && h != nil {
msanread(key, t.key.size)
}
// 如果map是空的,返回0指针和false
if h == nil || h.count == 0 {
if t.hashMightPanic() {
t.hasher(key, 0) // see issue 23734
}
return unsafe.Pointer(&zeroVal[0]), false
}
// map在执行写操作时,不允许读
if h.flags&hashWriting != 0 {
throw("concurrent map read and map write")
}
// 根据seed,计算key的哈希值
hash := t.hasher(key, uintptr(h.hash0))
m := bucketMask(h.B)
// 计算出key所在的bucket
b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + (hash&m)*uintptr(t.bucketsize)))
// 如果oldbuckets不为空,则此时map在扩容。
// 扩容期间,对应的key有可能还没有复制到新的bucket中,
// 所以需要扫描oldbuckets
if c := h.oldbuckets; c != nil {
// 如果不是扩1倍,说明只扩容了之前的一半
// 减半后的size才是oldbuckets的数据区间
if !h.sameSizeGrow() {
// There used to be half as many buckets; mask down one more power of two.
m >>= 1
}
oldb := (*bmap)(unsafe.Pointer(uintptr(c) + (hash&m)*uintptr(t.bucketsize)))
if !evacuated(oldb) {
b = oldb
}
}
// 取高8位的hash,定位所在bucket
top := tophash(hash)
bucketloop:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
// 如果最后一个bucket是空的,则不在对应的key,直接break
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
// bucket只能存放最多8个元素
// 如果是大key,则存在溢出桶,比对key时,需要加上溢出桶的数据
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
if t.key.equal(key, k) {
// 返回对应的value
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
if t.indirectelem() {
e = *((*unsafe.Pointer)(e))
}
return e, true
}
}
}
return unsafe.Pointer(&zeroVal[0]), false
}
五、插入
当形如 hash[k] 的表达式出现在赋值符号左侧时,该表达式也会在编译期间转换成 runtime.mapassign 函数的调用。
该函数与 runtime.mapaccess1 比较相似,我们将其分成几个部分依次分析,首先是函数会根据传入的键拿到对应的哈希和桶:
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
if h == nil {
panic(plainError("assignment to entry in nil map"))
}
// 竞态检查
if raceenabled {
callerpc := getcallerpc()
pc := funcPC(mapassign)
racewritepc(unsafe.Pointer(h), callerpc, pc)
raceReadObjectPC(t.key, key, callerpc, pc)
}
//
if msanenabled {
msanread(key, t.key.size)
}
if h.flags&hashWriting != 0 {
throw("concurrent map writes")
}
// 计算key的哈希值
hash := t.hasher(key, uintptr(h.hash0))
// Set hashWriting after calling t.hasher, since t.hasher may panic,
// in which case we have not actually done a write.
// 设置写标志
h.flags ^= hashWriting
if h.buckets == nil {
h.buckets = newobject(t.bucket) // newarray(t.bucket, 1)
}
again:
bucket := hash & bucketMask(h.B)
if h.growing() {
growWork(t, h, bucket)
}
// 计算hash所在的bucket
b := (*bmap)(add(h.buckets, bucket*uintptr(t.bucketsize)))
// 获得哈希的高8位
top := tophash(hash)
遍历桶的key,返回新key的存放位置。如果key重复,则value进行覆盖;如果key不存在, 则追加到bucket的尾部。
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
var inserti *uint8
var insertk unsafe.Pointer
var elem unsafe.Pointer
bucketloop:
for {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
// tophash不相同,需要判断是否为尾部
if isEmpty(b.tophash[i]) && inserti == nil {
// bucket的尾部,表明需要追加
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
}
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
if !t.key.equal(key, k) {
// key不匹配,继续顺着bucket向下查找
continue
}
// 如果key存在,后续需要进行覆盖
// 则对应的old value设置删除标志.
if t.needkeyupdate() {
typedmemmove(t.key, k, key)
}
elem = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
goto done
}
ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
如果溢出桶太多或者装载率过大,则哈希表扩容,然后重新定位key存放的位置。
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again // Growing the table invalidates everything, so try again
}
if inserti == nil {
// The current bucket and all the overflow buckets connected to it are full, allocate a new one.
newb := h.newoverflow(t, b)
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
elem = add(insertk, bucketCnt*uintptr(t.keysize))
}
// 在存放位置保存key
if t.indirectkey() {
kmem := newobject(t.key)
*(*unsafe.Pointer)(insertk) = kmem
insertk = kmem
}
// 在存放位置保存value
if t.indirectelem() {
vmem := newobject(t.elem)
*(*unsafe.Pointer)(elem) = vmem
}
// 如果当前键值对在哈希中不存在,哈希会为新键值对规划存储的内存地址,
// 通过 runtime.typedmemmove将键移动到对应的内存空间中并返回键对应值的地址 val。
// 如果当前键值对在哈希中存在,那么就会直接返回目标区域的内存地址
typedmemmove(t.key, insertk, key)
// 将插入的元素绑定到哈希表上
*inserti = top
// 元素计数器+1
h.count++
插入完成后,解除写操作标志。
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
done:
if h.flags&hashWriting == 0 {
throw("concurrent map writes")
}
// 写操作置位
h.flags &^= hashWriting
if t.indirectelem() {
elem = *((*unsafe.Pointer)(elem))
}
return elem
}
上述中,我们讲解了key的插入,接下来对哈希表扩容进行展开。
有上述代码可知,两种情况下会进行哈希扩容:
- 装载因子达到阈值(go设定6.5)。
- 溢出桶过多。
func hashGrow(t *maptype, h *hmap) {
// If we've hit the load factor, get bigger.
// Otherwise, there are too many overflow buckets,
// so keep the same number of buckets and "grow" laterally.
bigger := uint8(1)
if !overLoadFactor(h.count+1, h.B) {
bigger = 0
h.flags |= sameSizeGrow
}
oldbuckets := h.buckets
// 确定新的bucket数量, 和溢出桶
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
// 设置迭代的标志到old buckets
flags := h.flags &^ (iterator | oldIterator)
if h.flags&iterator != 0 {
flags |= oldIterator
}
// commit the grow (atomic wrt gc)
// 应用新的map配置
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
h.nevacuate = 0
h.noverflow = 0
if h.extra != nil && h.extra.overflow != nil {
// Promote current overflow buckets to the old generation.
if h.extra.oldoverflow != nil {
throw("oldoverflow is not nil")
}
h.extra.oldoverflow = h.extra.overflow
h.extra.overflow = nil
}
if nextOverflow != nil {
if h.extra == nil {
h.extra = new(mapextra)
}
h.extra.nextOverflow = nextOverflow
}
// the actual copying of the hash table data is done incrementally
// by growWork() and evacuate().
}
扩容时,旧的buckets指向oldbukcets后,不会立即进行数据的拷贝和迁移,具体的拷贝操作是在 runtime.evacuate中完成的,它会对传入桶中的元素进行再分配。
迁移完成后,oldbuckets和oldoverflow会被清空。
六、总结
Go使用拉链法解决哈希冲突问题,哈希表的访问、删除、修改和写入都在编译时转换成对应的runtime函数。key的哈希高8位存储在bucke中,当需要定位时,tophash就成了快速定位的缓存。
哈希的bucket只存储8个key-value,一旦超过8个,新的key-value就会存储到溢出桶中。虽然key-value的增加,溢出桶的数量和哈希的装载因子就会提升,达到阈值后会出发哈希表的扩容。 扩容时元素的迁移也是在写操作上增量进行的,所以不会造成性能的瞬间巨大抖动。
根据上述知识,尝试着来解答一个众所周知的结论:map并发不安全。反过来想,如果map是并发安全的,那么扩容就必然涉及到数据一致性问题。为了保证一致性,可能产生两种做法:
- 加锁。如需扩容,则需要等待扩容结束再释放锁,这种情况下,由于锁的竞争和扩容过程中数据迁移的同步执行过程,会导致读写性能相当差。
- 读写分离。数据库的优秀设计思想,这种方式取了一个中间值,并发安全且思路1那么慢。这种其实就是sync.map的实现思想,后续会有专文分析。
根据map实现并发安全的设计思路可知,并发下性能会有较大影响,尤其是哈希扩容时会产生巨大的瞬间抖动。根据职责单一原则,或者说保持底层语言的开放性,map设计成并发不安全来换取高性能是一种非常漂亮的设计。