通过源码分析Go的基本类型-String(字符串),源代码版本:go 1.17.3.
一、数据结构
字符串是Go的基本类型之一,是一串只读的、连续的内存空间。对于代码中赋值的字符串,编译器会将其替换为只读数据STODATA。
$ cat main.go
package main
func main() {
str := "hello"
println([]byte(str))
}
$ GOOS=linux GOARCH=amd64 go tool compile -S main.go
...
go.string."hello" SRODATA dupok size=5
0x0000 68 65 6c 6c 6f hello
...
上面的代码可以看到,赋值语句hello有标记STODATA,size=5。
通过reflect/value.go中对StringHeader的定义可以看到:
type StringHeader struct {
Data uintptr
Len int
}
字符串由一个头部指针和Len组成,相比slice来说,只缺少一个容量cap的定义,所以常解释字符串是一个只读的字符切片。
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
由于字符串是只读的,那么我们就不可以直接在原有的字符串上进行修改,只能通过重建、拷贝的方式达到形式上的修改。
二、字符串的解析
语法分析器在处理字符串时,会对源文件中的字符串进行切片和分组,将字符串解析为Token序列。在Go中我们用双引号和反引号定义字符串:
str1 := "this is a string"
str2 := `this is another
string`
双引号下,不能换行。如果需要逃逸双引号,则需要通过增加”\“进行转义。反引号则可以突破单行限制,但是反引号无法通过”\“逃逸。
不同的声明方式,需要不同的解析方法。Go的cmd/compile/internal/syntax/scanner.go中定义了两种声明方式下不同的解析方法:
func (s *scanner) next() {
...
switch s.ch {
...
case '"':
s.stdString()
case '`':
s.rawString()
双引号声明的字符串,通过stdString进行解析。
func (s *scanner) stdString() {
ok := true
s.nextch()
for {
if s.ch == '"' {
s.nextch()
break
}
if s.ch == '\\' {
s.nextch()
if !s.escape('"') {
ok = false
}
continue
}
if s.ch == '\n' {
s.errorf("newline in string")
ok = false
break
}
if s.ch < 0 {
s.errorAtf(0, "string not terminated")
ok = false
break
}
s.nextch()
}
s.setLit(StringLit, ok)
}
从中可以看出,双引号定义字符串有以下特点:
- 双引号开始和结尾;
- 反斜杠”\“可以逃逸双引号;
- 不能换行。
反引号的解析则使用的rawString方法。
func (s *scanner) rawString() {
ok := true
s.nextch()
for {
if s.ch == '`' {
s.nextch()
break
}
if s.ch < 0 {
s.errorAtf(0, "string not terminated")
ok = false
break
}
s.nextch()
}
s.setLit(StringLit, ok)
}
通过源码,可以看到反引号只能以反引号开始和结尾,且不能被转义。支持换行等其他字符。
而无论是反引号还是双引号,字符串最后都会通过setList转换成Token序列,最后传递到go/constant/value.go的MakeFromLiteral中被处理成字符串:
func MakeFromLiteral(lit string, tok token.Token, zero uint) Value {
if zero != 0 {
panic("MakeFromLiteral called with non-zero last argument")
}
switch tok {
...
case token.STRING:
if s, err := strconv.Unquote(lit); err == nil {
return MakeString(s)
}
default:
panic(fmt.Sprintf("%v is not a valid token", tok))
}
return unknownVal{}
}
strconv.Unquote对字符串做了很多的处理,包括对字符转换、字符编码一致性检查等,此处不展开,感兴趣的可以定位到源代码:strconv/quote.go Line 391.
三、字符串拼接
Go通过关键字”+”拼接两个字符串,前面说到字符串是只读的,那么拼接就必然发生了新建内存和内容的拷贝。
编译器检测到符号”+”后,会将其对应的OADD指令转换为:OADDSTR,然后调用``src/cmd/compile/internal/walk/expr.go`中的walkAddString生成用于拼接字符串的代码:
func walkExpr1(n ir.Node, init *ir.Nodes) ir.Node {
switch n.Op() {
default:
ir.Dump("walk", n)
base.Fatalf("walkExpr: switch 1 unknown op %+v", n.Op())
panic("unreachable")
...
case ir.OADDSTR:
return walkAddString(n.(*ir.AddStringExpr), init)
...
func walkAddString(n *ir.AddStringExpr, init *ir.Nodes) ir.Node {
c := len(n.List)
if c < 2 {
base.Fatalf("walkAddString count %d too small", c)
}
buf := typecheck.NodNil()
...
// build list of string arguments
args := []ir.Node{buf}
for _, n2 := range n.List {
args = append(args, typecheck.Conv(n2, types.Types[types.TSTRING]))
}
var fn string
if c <= 5 {
// small numbers of strings use direct runtime helpers.
// note: order.expr knows this cutoff too.
fn = fmt.Sprintf("concatstring%d", c)
} else {
// large numbers of strings are passed to the runtime as a slice.
fn = "concatstrings"
t := types.NewSlice(types.Types[types.TSTRING])
// args[1:] to skip buf arg
slice := ir.NewCompLitExpr(base.Pos, ir.OCOMPLIT, ir.TypeNode(t), args[1:])
slice.Prealloc = n.Prealloc
args = []ir.Node{buf, slice}
slice.SetEsc(ir.EscNone)
}
cat := typecheck.LookupRuntime(fn)
r := ir.NewCallExpr(base.Pos, ir.OCALL, cat, nil)
r.Args = args
r1 := typecheck.Expr(r)
r1 = walkExpr(r1, init)
r1.SetType(n.Type())
return r1
}
可以看到:
- 如果需要拼接的字符串小于等于5个,那么匹配concatstring{2,3,4,5};
- 如果超过5个,则匹配concatstrings方法, 将字符串转换成切片类型进行处理
无论是哪种方式,最后都会调用src/runtime/string.go中的concatstrings,遍历传入的切片数组,过滤掉空字符后进行拼接。
func concatstrings(buf *tmpBuf, a []string) string {
idx := 0
l := 0
count := 0
for i, x := range a {
n := len(x)
if n == 0 {
continue
}
if l+n < l {
throw("string concatenation too long")
}
l += n
count++
idx = i
}
if count == 0 {
return ""
}
// If there is just one string and either it is not on the stack
// or our result does not escape the calling frame (buf != nil),
// then we can return that string directly.
if count == 1 && (buf != nil || !stringDataOnStack(a[idx])) {
return a[idx]
}
s, b := rawstringtmp(buf, l)
for _, x := range a {
copy(b, x)
b = b[len(x):]
}
return s
}
如果非空字符串长度为1,且数据不在栈上,则直接返回该字符串,否则需要对字符串进行拷贝操作。
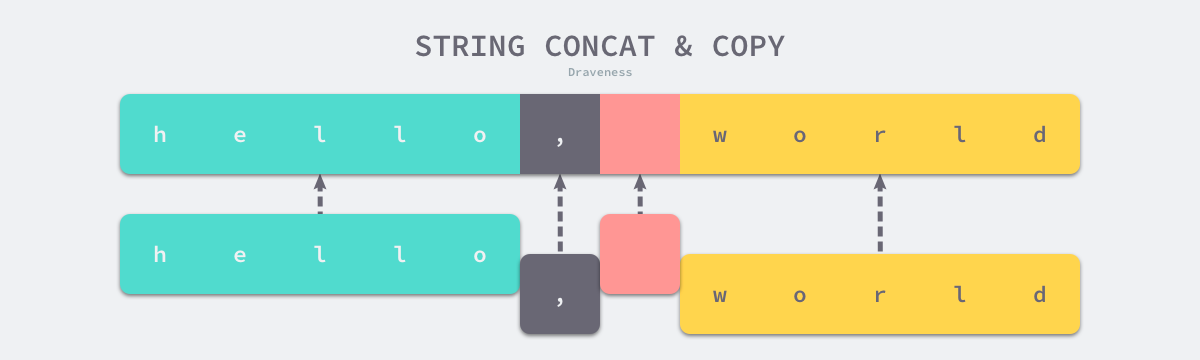
可以看到,字符串拼接时分配了一段新的连续内存空间,然后将旧数据copy过去,新的字符串和旧的没有任何关联。 在应用中,一旦拼接过大的字符串,则其带来的内存损耗和COPY开销是不可忽略的。
四、 类型转换
Go中,字符串和[]byte之间的转换很常见,尤其是在json数据转换时,经常需要相互转换。
从字符数组到字符串的转换,调用的是src/runtime/string.go的slicebytetostring方法。
func slicebytetostring(buf *tmpBuf, ptr *byte, n int) (str string) {
if n == 0 {
// Turns out to be a relatively common case.
// Consider that you want to parse out data between parens in "foo()bar",
// you find the indices and convert the subslice to string.
return ""
}
if raceenabled {
// 竞态检查
racereadrangepc(unsafe.Pointer(ptr),
uintptr(n),
getcallerpc(),
funcPC(slicebytetostring))
}
if msanenabled {
msanread(unsafe.Pointer(ptr), uintptr(n))
}
if n == 1 {
p := unsafe.Pointer(&staticuint64s[*ptr])
if sys.BigEndian {
p = add(p, 7)
}
stringStructOf(&str).str = p
stringStructOf(&str).len = 1
return
}
var p unsafe.Pointer
if buf != nil && n <= len(buf) {
p = unsafe.Pointer(buf)
} else {
p = mallocgc(uintptr(n), nil, false)
}
stringStructOf(&str).str = p
stringStructOf(&str).len = n
memmove(p, unsafe.Pointer(ptr), uintptr(n))
return
}
如果数组的长度是0或者1,则可以简单操作返回。否则,需要为返回的字符串分配内存,并将值copy过去。 这里如果缓冲区够存储,则使用缓冲区的内存,否则需要重新申请。
如果是字符串转[]byte时,则需要使用stringtoslicebyte方法:
func stringtoslicebyte(buf *tmpBuf, s string) []byte {
var b []byte
if buf != nil && len(s) <= len(buf) {
*buf = tmpBuf{}
b = buf[:len(s)]
} else {
b = rawbyteslice(len(s))
}
copy(b, s)
return b
}
同样的,如果缓冲区不够的情况下,会申请新的内存存储切片类型的结果,分配到内存后,同样的进行值的拷贝。
当我们需要修改字符串时,需要借助字符串转换成字符切片,然后对切片进行修改后重新转换成字符串,所以整个过程中都伴随着内存的分配和拷贝的带来的压力。