本文尝试从Libra的共识机制来解析BFT的工作机制。
1. BFT是什么
首先来一段百科定义:
拜占庭位于如今的土耳其的伊斯坦布尔,是东罗马帝国的首都。由于当时拜占庭罗马帝国国土辽阔,为了达到防御目的,每个军队都分隔很远,将军与将军之间只能靠信差传消息。 在战争的时候,拜占庭军队内所有将军和副官必须达成一致的共识,决定是否有赢的机会才去攻打敌人的阵营。但是,在军队内有可能存有叛徒和敌军的间谍,左右将军们的决定又扰乱整体军队的秩序。在进行共识时,结果并不代表大多数人的意见。这时候,在已知有成员谋反的情况下,其余忠诚的将军在不受叛徒的影响下如何达成一致的协议,拜占庭问题就此形成。
也就是说,群体中可能存在反叛分子,如果全部抱团,则战斗力最强;否则都是一种削弱。
BFT用两个维度来解决这个问题:
- 安全性。所有忠诚的将军达成一致。
- 活性。结果一定会产生,且所有节点最终达成结果一致。
那么为了保证安全性,活性是在所有情况下的结果。为了保证两者,容易提出两个问题:
- 最多可以容忍多少个反叛分子
- 在分布式情况下,结果产生的时间限制是多少。
1/3容忍度
众所周知,BFT的容忍度是小于总节点树的1/3,这里我们尝试着推导。
拜占庭将军问题上,假设要决策进攻还是撤退,忠诚将军只能按照收到的大部分将军传过来的命令来统计大多数人选择的命令(不能等全部,存在恶意投票的情况下会导致卡住),然后自己执行这条命令。
那么为了保证所有忠诚将军执行结果一致,那么设胜出的投票数最少要达到X个,忠诚将军才能放心,因为他知道只要达到X个,其他忠诚将军就可以获得一个正确的大多数命令。
在这个过程中,每个将军会统计自己收到的命令。那么就会有这样的情况,反叛将军给A将军同步出进攻命令,给B同步出撤退命令,A得到进攻的投票+1,B得到撤退的投票+1。也就是说如果X只需大于n/2+1,那么结果会被反叛将军主导。
现在有结果进攻和撤退,如果X=n/2+1,那么这个结果可能就来自反叛将军发出的对立命令,最终结果被反叛将军主导了。
提取其中关键的数据:
- 总人数
- 最少票数不能超过忠诚将军数,否则反叛将军只要全部不投票,投票就将进行不下去
- 要保证忠诚将军的结果为最终结果,则必须要超过一般的忠诚将军发出了投票
- 反叛将军的选择是任意的,可能是进攻,也可能是撤退
转换为函数表达式:
1 => n = f + h
2 => h >= x
3 => x > h/2
3+4 => x > h/2 + f
推演
1 & 3+4 => h >= h/2 +f
=> h+h/2 >= h/2+h/2+f
=> 1.5h > n
=> h > 2/3 * n
=> f < 1/3 * n
上述是数学的推导, 换个角度,从逻辑上来推导。
如果要保证结果是忠诚将军所选择的,那么x中忠诚将军的票数就要超过反叛将军,只有这样才能排除反叛将军左右摇摆的不稳定因素。
那么如果f=1/3 * n,最坏情况下,1/3 * n的忠诚将军阵亡导致不能投票,所有的反叛将军投票结果和忠诚将军对立,那么忠诚将军票 = 反叛将军票数,投票卡死。
破坏上述临界点即可保证忠诚将军的必胜,即f< 1/3 * n. 要注意的是,忠诚将军指得是人数多的一方,而不是道德上的划分。
Leader轮换
BFT的容错率是小于1/3,那么如果大于这个值,就会导致共识无法达成,可能两种原因:
- 节点不投票。投票超时也算做不投票
- 节点给不同节点投不同票。
其中2通过引入数字签名解决。那么1如何处理呢?
不投票两种原因:
- 节点验证不通过,不认可leader的发起的共识
- 节点掉线了。
问题2无法自动处理,只能通过启动节点来修正,所以共识机制不处理此类异常。问题1如何处理呢?leader可能是好,也可能是坏,无法衡量的情况下最佳的选择就是换leader。
2. 两阶段确认的PBFT
在讲解Libra的共识机制前,先了解最常用和基础PBFT。
PBFT中文为实用拜占庭容错(Practical Byzantine Fault Tolerance),是BFT中最常见的共识模型,很多变种都是基于PBFT。
每个共识轮次,包括四个阶段:
- request:触发leader发起提案
- pre-prepare:leader准备提案,并把提案广播给所有节点.因为不需要和其他节点交互,所以也有很多共识中将1和2视为第一个轮次。
- prepare:节点要把自己的vote广播给其他节点,所以消息复杂度是O(N^2),同时会对收到的所有vote进行统计
- commit:当这个提案达到2f+1的vote时,节点会认为这个提案取得了认可,这时候,当前节点会通知所有其他节点他打算提交(commit)这个提案,commit消息不但要表明自己接收提案,还必须包含自己收集到的2f+1个vote。
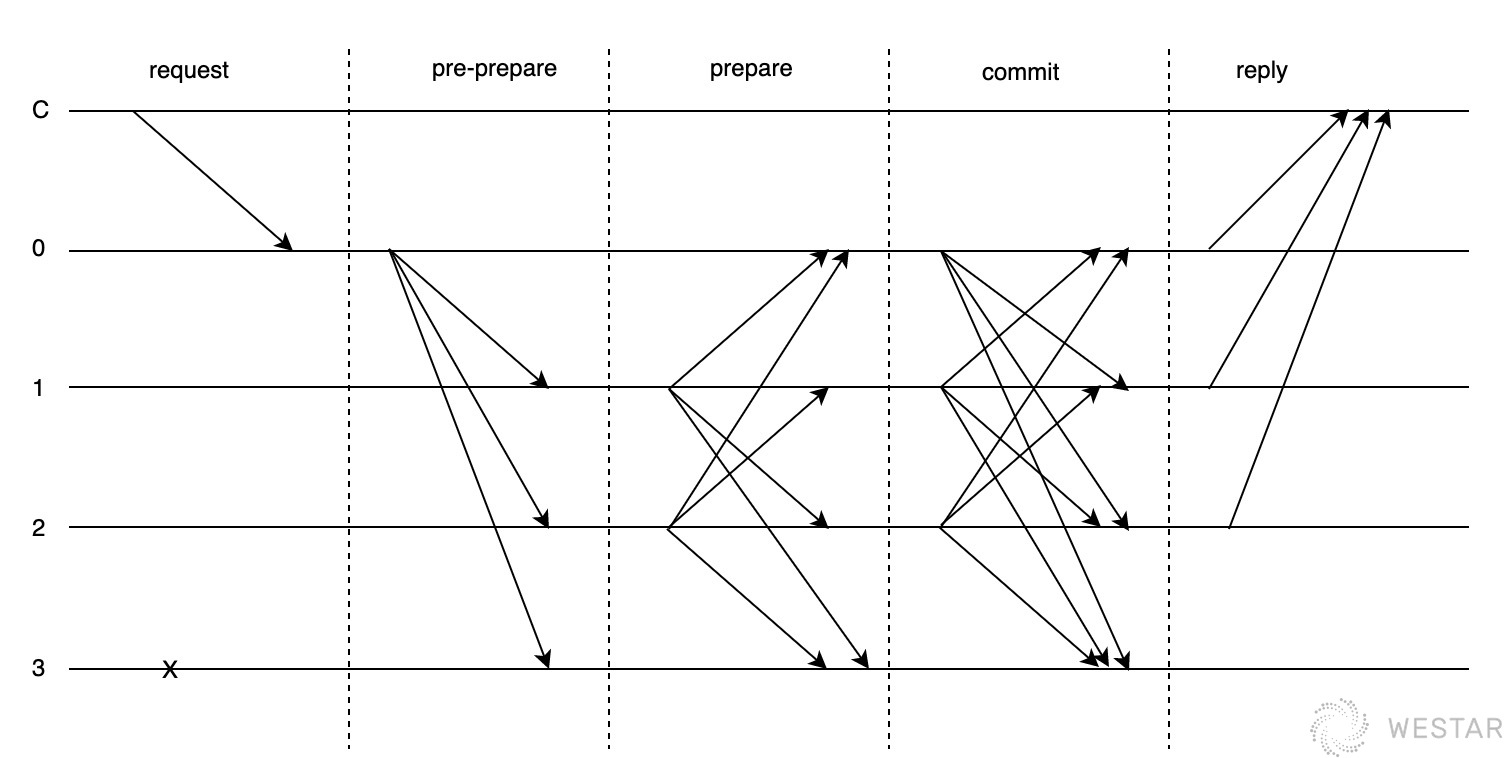
在上图中,C对应leader,0,1,2,3是4个参与投票的节点。 leader发出自己的提案,其他节点收到提案后发出自己的投票,然后所有节点开始收集投票,待收集到的投票达到2f+1后,发出commit,最终leader收集到不少于2f+1的commit后回复共识成功,本轮次共识结束。
期间发生了两次投票,第一次是其他节点对提案的投票,第二次是其他节点收集到第一轮次投票后发出的commit。那么为什么需要两轮呢?
接下来假设只发生一轮次投票。
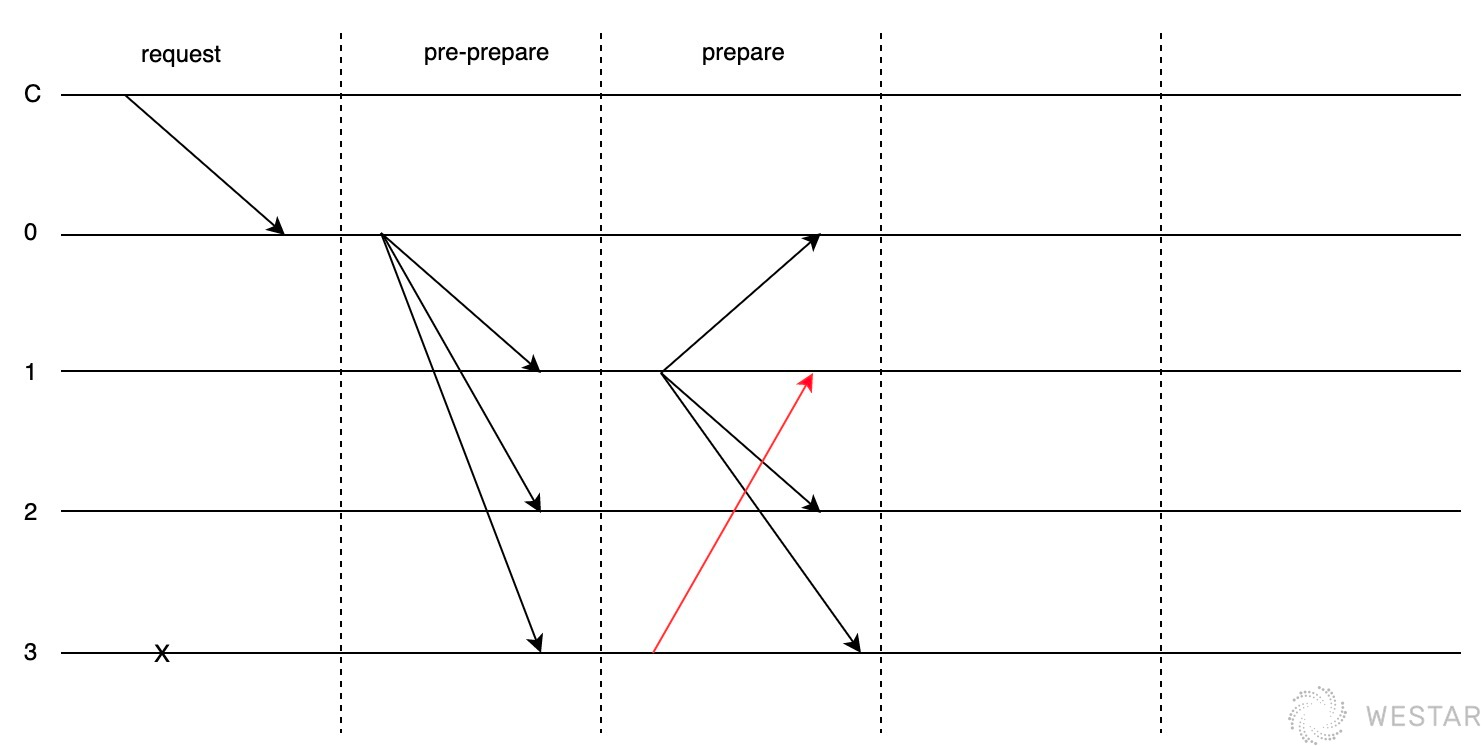
同样的,leader发出提案后,节点0、1、3均发出vote,然后节点3成为拜占庭节点(此时f=1,满足f<4/3)。
节点2虽然为非拜占庭节点,但是由于网络原因,没有及时发出vote。 此时节点1统计投票数为3(等于2f+1),认为共识已经达成一致。但实际没有,只有2个非拜占庭节点达成一致(2 < 2f+1)。
此时节点2上线,并发起新一轮共识,节点0和节点3同意重新共识,节点1反对,应为节点1认为这个提案已经共识了。那么新的提案就会导致节点1做为非拜占庭节点的结果和其他非拜占庭节点结果不一致。 所以一轮投票无法达成共识。
那么增加一轮投票,也就是PBFT中的commit阶段。
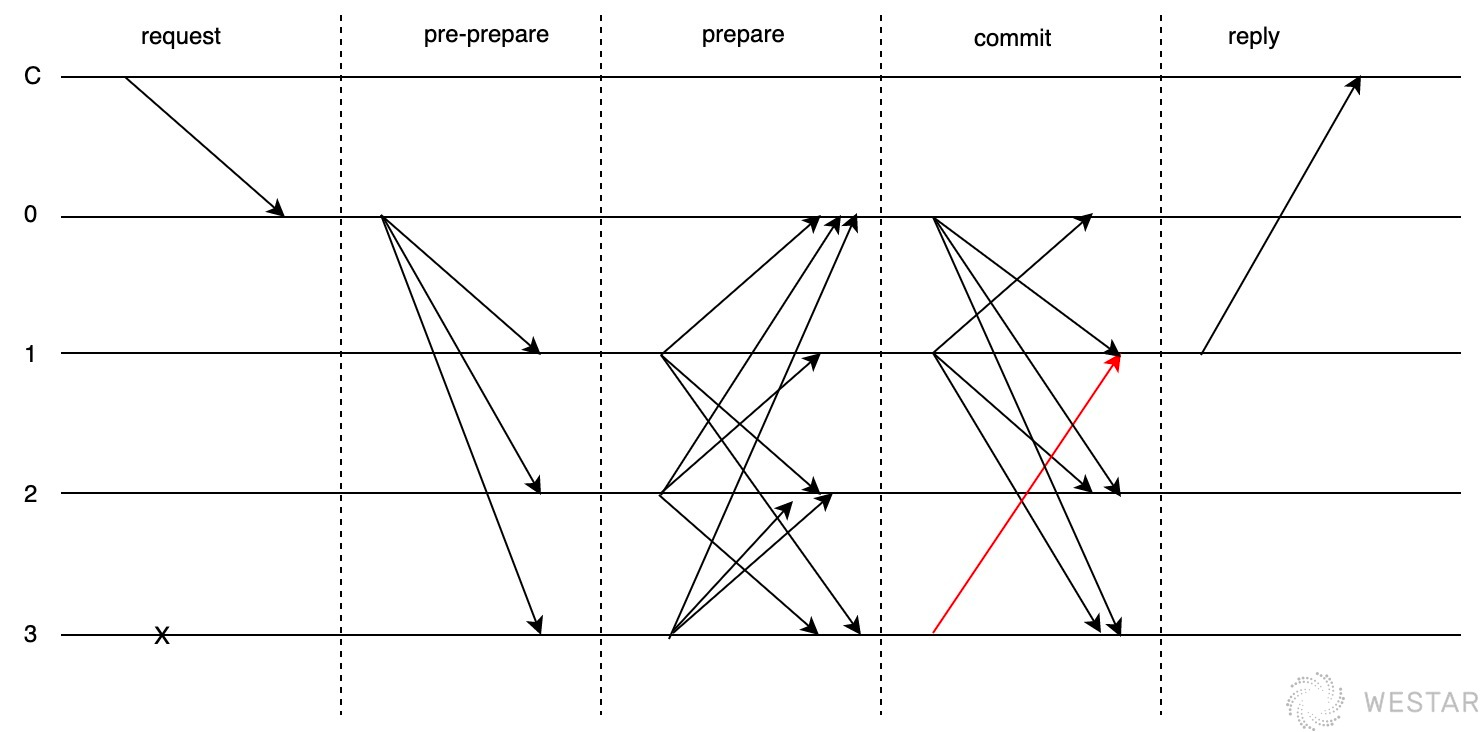
如果节点3在commit阶段成为拜占庭节点,那么也会导致结果的不一致。
为解决这一问题,PBFT协议设计在commit中需要携带prepare中获得的投票,commit中有vote,vote中有proposal,这样用一个O(n*3)的消息复杂度确保了共识的一致性。
3. 三阶段确认的Hotstuff
PBFT通过在第二阶段的commit阶段,携带第一阶段的vote来确保自己的诚实,这一方式带来了很大的消息复杂度,尤其会对分布式网络产生巨大的数据传输负担。
LibraBFT通过选择hotstuff容错算法实现的门限签名+三阶段确认来减少PBFT中的消息复杂度。
在了解门限签名之前,先引入安全多方计算。借用经典问题”百万富翁问题”来解释安全多方计算的工作:
两个百万富翁想知道谁更富有,而不希望别人知道自己资产的真实数额,怎么提供这个证明。
具体怎么实现,本文不讨论。但是从上述信息中可以提取到安全多方计算的部分特征:多方参与、正确性、隐私性。
那么假设一个用安全多方计算来实现数字签名的场景:
- 密钥生成。所有参与方联合计算出一个群体公钥,个体的私钥是不相同且不公开的。
- 生成签名。每个参与方用自己的私钥对公开的待签数据生成数字签名,并公开待签数据和数字签名。
- 验证签名。验证者收集到所有参与方的数字签名后,可以通过群体公钥进行验证。
这中基于安全多方计算思想构造的签名协议就是门限签名。
对应到hotstuff中,参与本轮次共识的所有节点可以计算出一个群体公钥,接下来共识节点使用自己的私钥对提案进行签名并广播,同一个提案收集到x(BFT中x>=2f+1)个节点签名后,可以构造出一个可被群体公钥验证的总签名。
这样总签名的投票就是:提案+总签名(此处省略了共识中轮次、区块高度等信息),大大减少了PBFT中的投票size。
Hotstuff比PBFT多了一轮投票阶段,其位于prepare和commit阶段的中间,称之为pre-commit阶段。 具体来看投票过程:
- prepare阶段:leader将包含自己的“提案+前一个commitQC”的消息msg1广播给所有节点
- pre-commit阶段:leader收到了2f+1个节点“通过msg1提案”的签名消息,然后使用这些签名构造一个“prepareQC总签名”的消息msg2,并将msg2广播给所有节点,让他们对自己构造的prepareQC进行验证
- commit阶段:leader收到了2f+1个节点“msg2的prepareQC验证通过”的签名消息,然后使用这些签名又构造成一个“pre-commitQC总签名+提交提案”的消息msg3,并广播给所有节点pre-commitQC进行验证
- decide阶段:leader收到了2f+1个节点“msg3的pre-commitQC验证通过”的签名消息,这个时候等于leader收到共识达成一致的证明,然后使用这些签名正式构造一个commitQC总签名的消息msg4,广播给所有节点
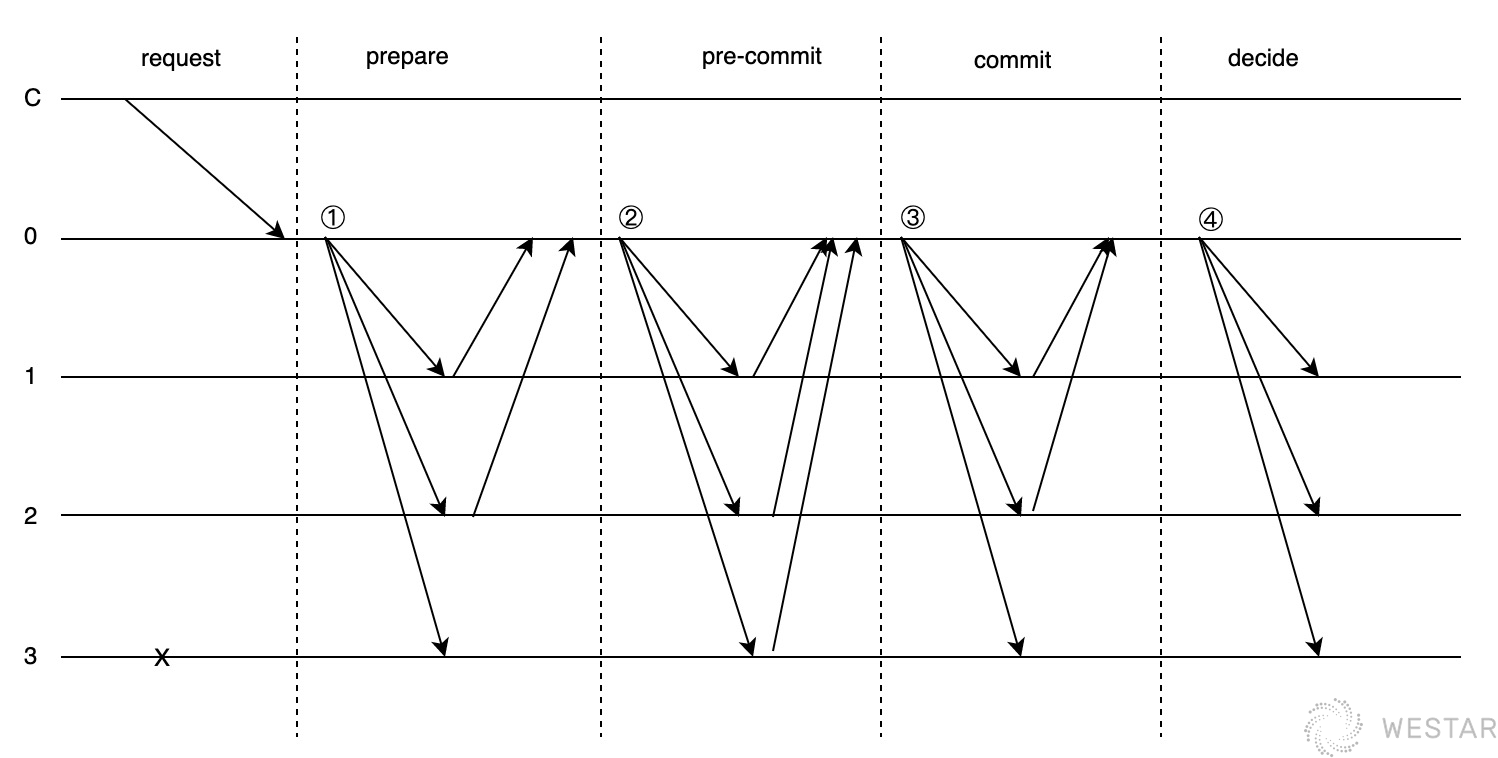
leader负责主动本轮次共识的达成,其他节点只需要参与leader发出的消息的验证,并给出自己的投票即可。
从上可以看出,prepare阶段和PBFT一致,那么pre-commit+commit等效于PBFT中commit阶段。pre-commit阶段就是将prepare阶段的投票结果做了一次共识,替代了PBFT中各投票节点发出的commit消息中的prepare votes。
链式Hotstuff
区块链的区块都需要共识,所以整体来看,三阶段的确认是一个链式的过程。
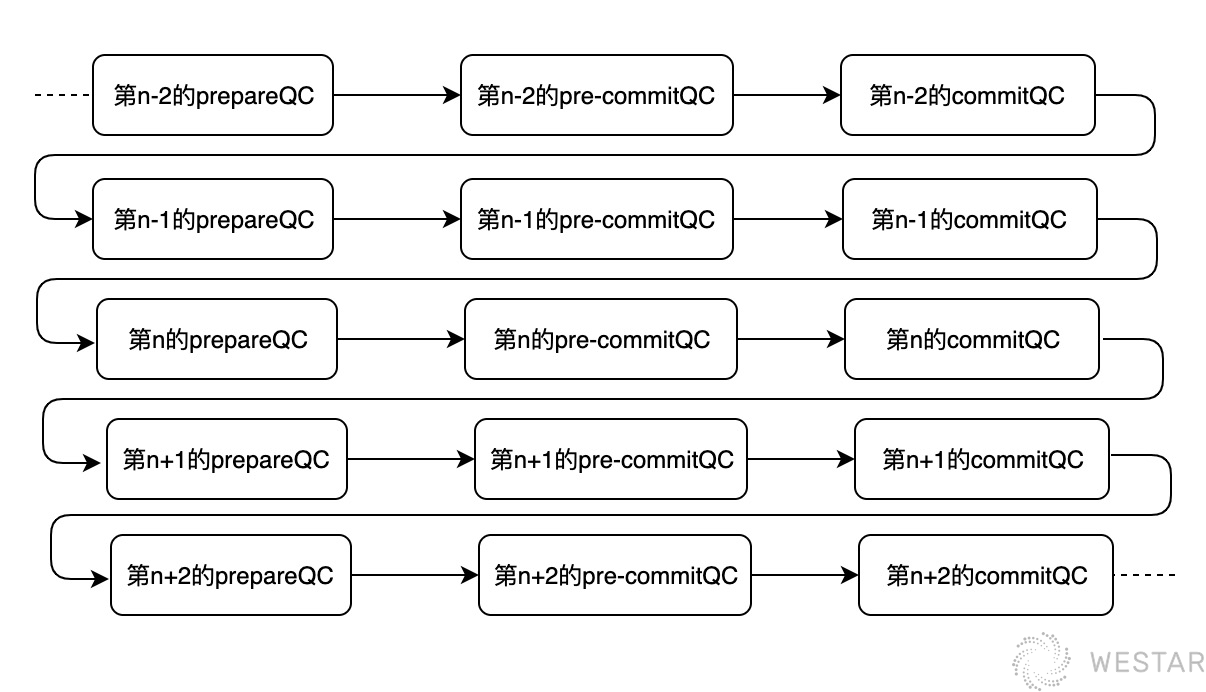
第n-2个区块需要三阶段确认,第n-1个区块需要三阶段确认,等等。
对应到Libra中的区块,可以看到其共识信息如下:
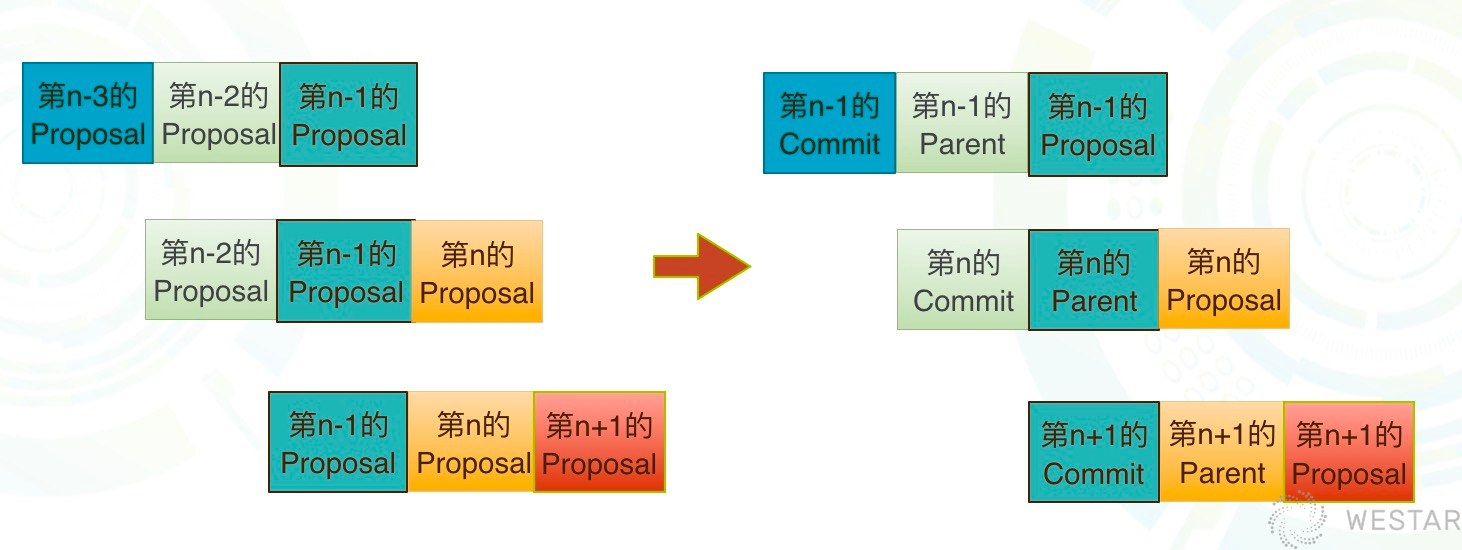
Libra在每一轮投票中,既会校验当前提案的Block,同时也会对爷爷(n-2)Block达成共识。 这样,爷爷Block就会被commit,并把Block包含的Transaction以及涉及的用户状态存储到DB中。
所以Libra的持久化存储中区块高度要比共识的Block低2个位置。因为后来两个高度的Block还没有达成共识,分别处于pre-commitQC阶段和prepareQC阶段。 Libra实现的共识流程大概是这样的:
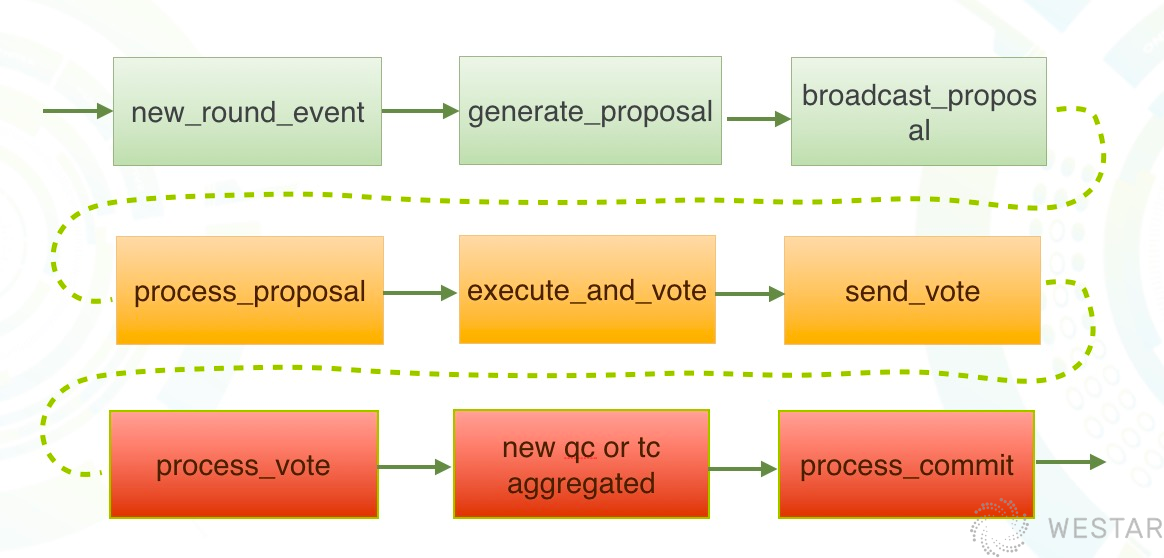
上图中:
- 绿色代表本轮次的leader,负责为Block创建并发起提案;
- 黄色是参与共识的验证节点,负责验证提案的合法性,并发出自己的投票;
- 红色是下一轮次的leader,负责收集投票,构建QC,并处理commit。等轮到下一轮次,作为leader构建Block,发起提案。
那么Libra中绿色和红色节点是怎么确定成为leader的呢?我们接着往下。
Leader选举
引入定义:
- Proposer,提案者,对应leader,但是提案者可能有多个,所以改一个称呼。
- validator,参与共识的节点。
Libra实现了三种Proposer选择策略:
- FixedProposer: 固定一个节点作为Proposer,一般用于测试。
- RotatingProposer: 一批validators,轮流成为Proposer。
- MultipleOrderedProposers: 一种加权随机的轮换算法,每个轮次有一组Proposer,每个proposer存在优先级,非拜占庭节点会给优先级最高的Proposer投票。
更新一组proposer
更换的核心:确保每个节点在每个轮次用只能看到相同的一组Proposer。
Libra内置validators合约,可以通过tx调用add_validator和remove_validator更新validators。由于是tx的形式,所以validators的变更需要等改tx所在区块commit后才能生效。
生效后,所有节点会更新自己的validators。